Ze-Feng Gao / 高泽峰I am a Postdoctoral Researcher at the Gaoling School of Artificial Intelligence at Renmin University of China. Under the guidance of Prof. Ji-Rong Wen and Prof. Hao Sun, my research focuses on several areas, including model compression, data compression, and the development of pre-training language models based on tensor networks. I hold a Ph.D. in Science from the Department of Physics at Renmin University of China, where I had the privilege of working under the supervision of Prof. Zhong-Yi Lu. With my background in physics and current research interests in artificial intelligence, I bring a multidisciplinary approach to my work. I am passionate about exploring innovative techniques for compressing models and data, as well as leveraging tensor networks to enhance the performance of pre-training language models. Email: zfgao@ruc.edu.cn GitHub / Google Scholar / DBLP / Zhihu |

|
Education |
Work Experience |
Invited talk |
{kind=link}
Research ProjectsLightweight Fine-tuning Strategy for Multimodal Pre-training Models based on Matrix Product Operator Method, Role: PI Lightweight Fine-tuning and Model Scaling Approach for Large Scale Pre-trained Language Models, Role: PI , Role: Participate Some Issues in Multibody Localization, Role: Participate Several Problems in Quantum Impurity Systems based on Natural Orbital Reformation Groups in Quantum Impurity Systems, Role: Participate |
Publications
2023 |
|
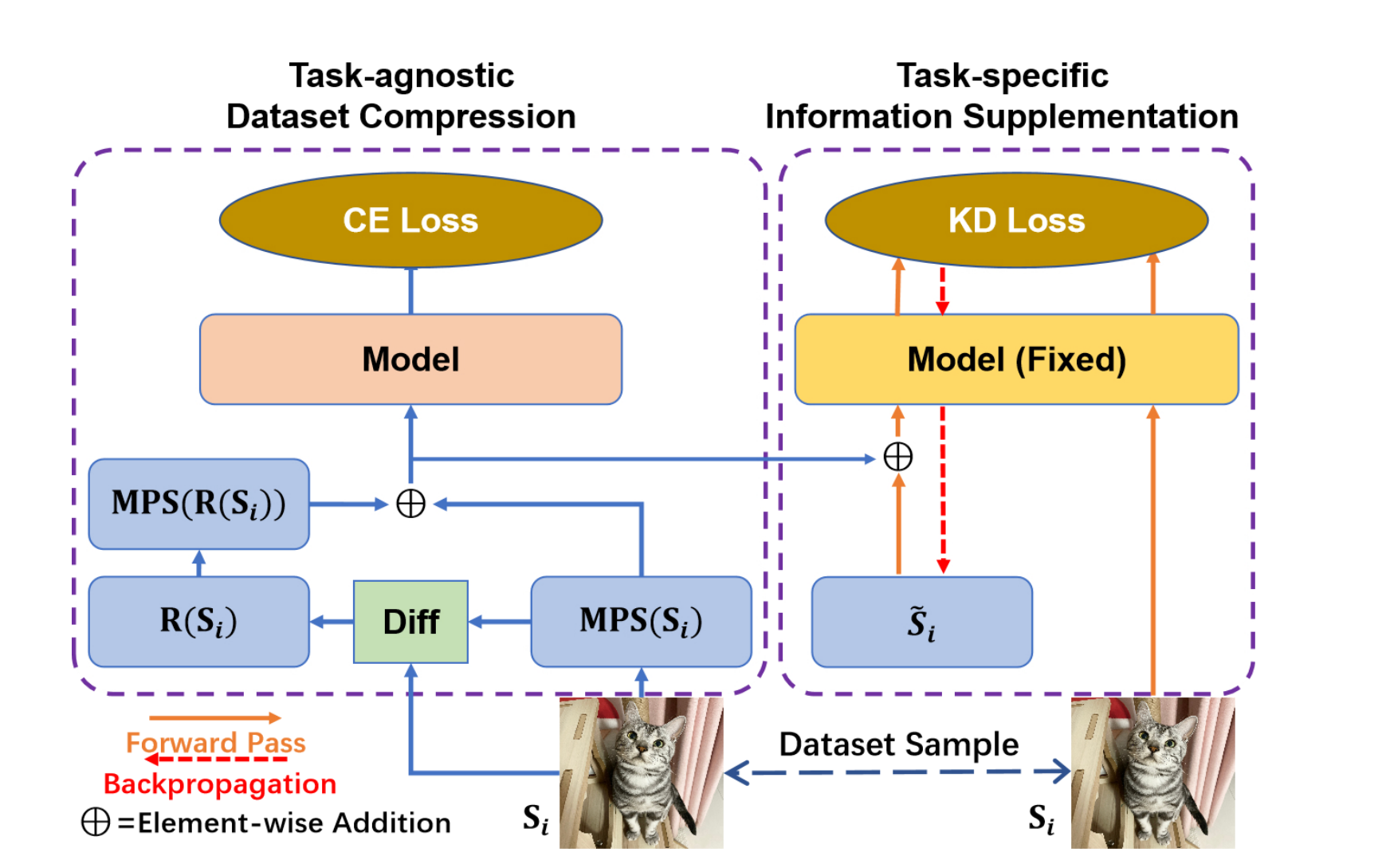
Compression Image Dataset Based on Multiple Matrix Product StatesZe-Feng Gao, Peiyu Liu, Wayne Xin Zhao, Zhi-Yuan Xie, Ji-Rong Wen and Zhong-Yi Lu Future of Information and Communication Conference (FICC2024), 2023 paper / In this paper, we present an effective dataset compression approach based on the matrix product states (short as MPS) and knowledge distillation. MPS can decompose image samples into a sequential product of tensors to achieve task-agnostic image compression by preserving the low-rank information of the images. Based on this property, we use multiple MPS to represent the image datasets samples. Meanwhile, we also designed a task-related component based on knowledge distillation to enhance the generality of the compressed dataset. |
|
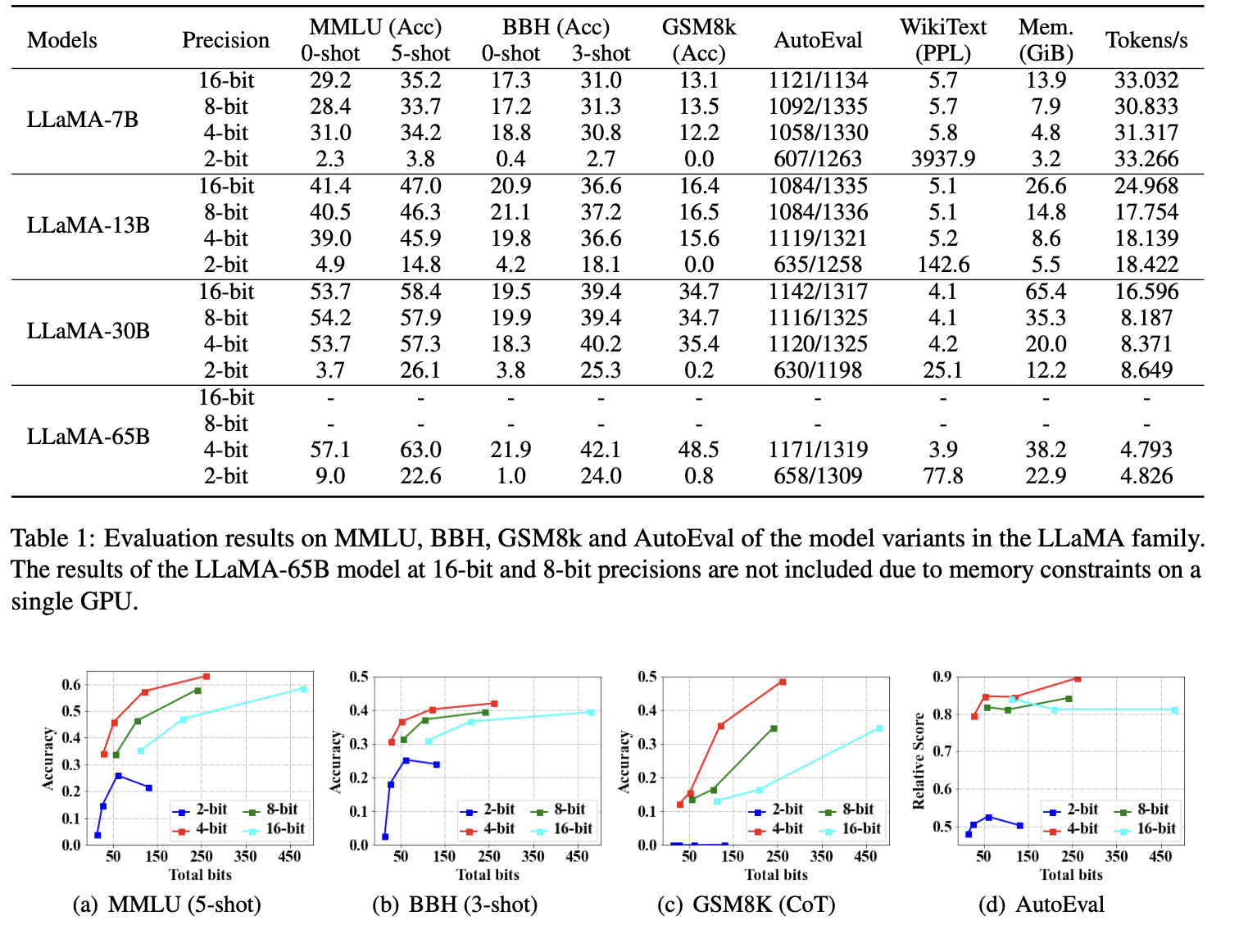
Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical StudyPeiyu Liu, Zikang Liu, Ze-Feng Gao, Dawei Gao, Wayne Xin Zhao,Yaliang Li, Bolin Ding, Ji-Rong Wen Arxiv, 2023 paper / arxiv / This work aims to investigate the impact of quantization on \emph{emergent abilities}, which are important characteristics that distinguish LLMs from small language models. Specially, we examine the abilities of in-context learning, chain-of-thought reasoning, and instruction-following in quantized LLMs. |
|
Small Pre-trained Language Models Can be Fine-tuned as Large Models via Over-ParameterizationZe-Feng Gao, Kun Zhou,Peiyu Liu, Wayne Xin Zhao, Ji-Rong Wen Annual Meeting of the Association for Computational Linguistics (ACL2023), Oral (Nominated for Best Paper Reward), 2023 paper / code / link / In this paper, we focus on just scaling up the parameters of PLMs during fine-tuning, to benefit from the over-parameterization but not increasing the inference latency. Extensive experiments have demonstrated that our approach can significantly boost the fine-tuning performance of small PLMs and even help small PLMs outperform 3x parameterized larger ones. |
|
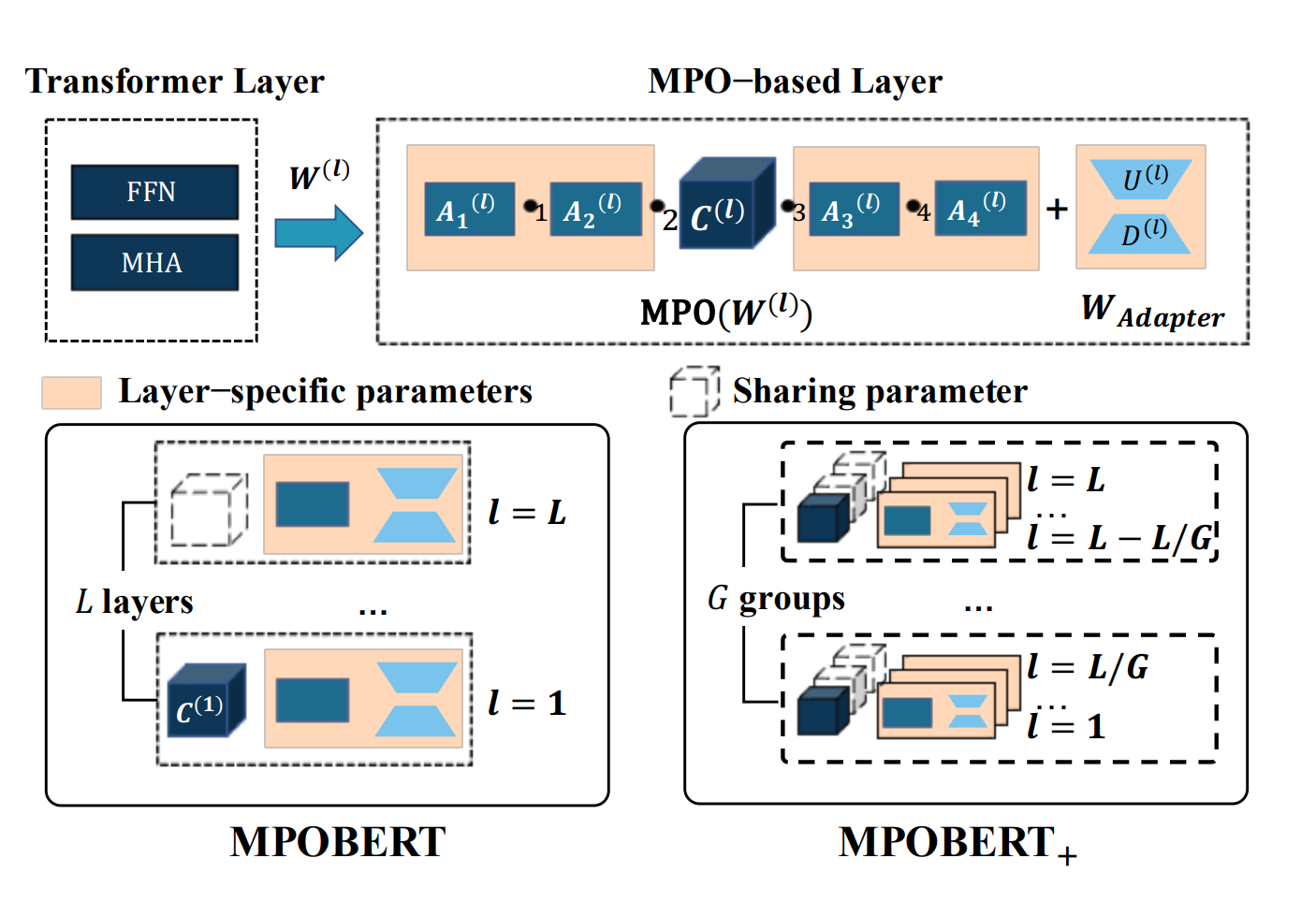
Scaling Pre-trained Language Models to Deeper via Parameter-efficient ArchitecturePeiyu Liu*, Ze-Feng Gao*, Wayne Xin Zhao, Ji-Rong Wen Arxiv, 2023 paper / arxiv / In this paper, we propose a parameter-efficient pre-training approach that utilizes matrix decomposition and parameter-sharing strategies to scale PLMs. Extensive experiments have demonstrated the effectiveness of our proposed model in reducing the model size and achieving highly competitive performance (i.e. with fewer parameters than BERT-base, we successfully scale the model depth by a factor of 4x and even achieve 0.1 points higher than BERT-large for GLUE score). |
|
2022 |
|
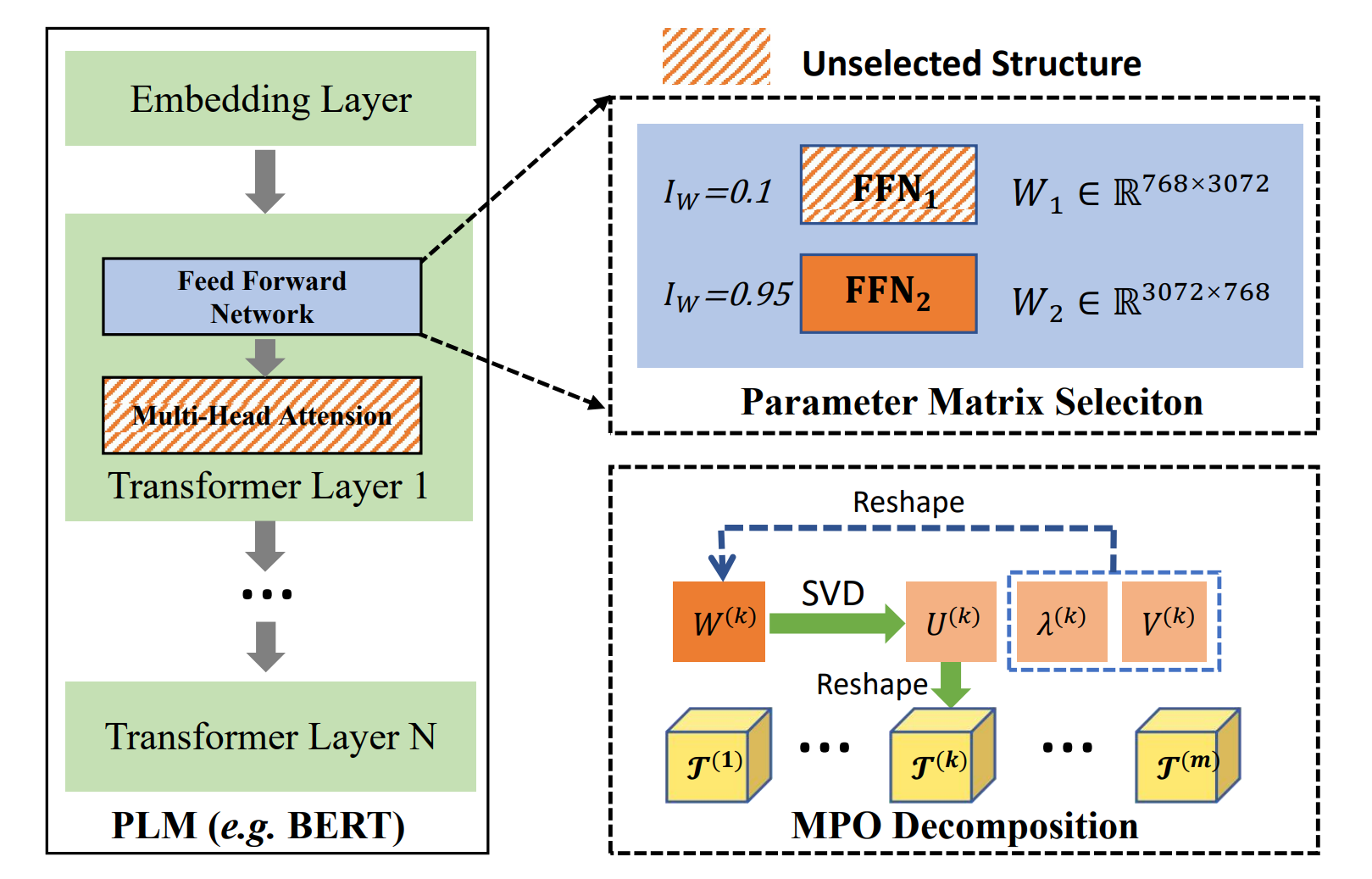
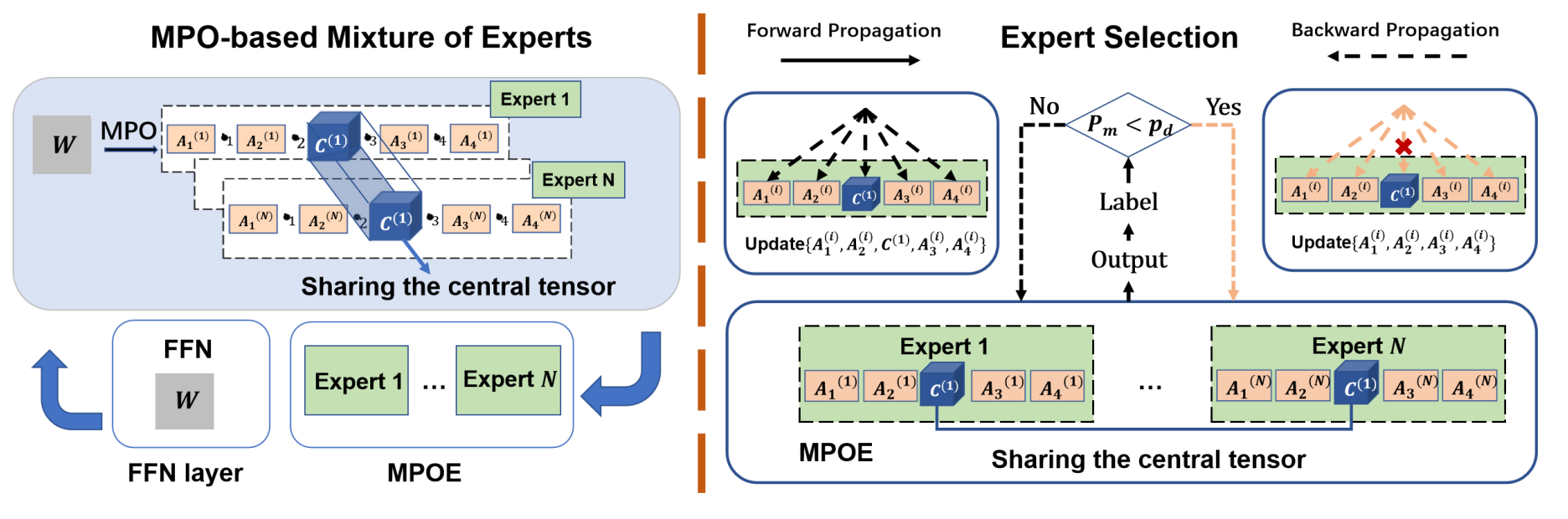
Parameter-Efficient Mixture-of-Experts Architecture for Pre-trained Language ModelsZe-Feng Gao*, Peiyu Liu*, Wayne Xin Zhao#, Zhong-Yi Lu, Ji-Rong Wen International Conference on Computational Linguistic (COLING2022), Oral Presentation, 2022 paper / arxiv / code / In this paper, we can reduce the parameters of the original MoE architecture by sharing a global central tensor across experts and keeping expert-specific auxiliary tensors. We also design the gradient mask strategy for the tensor structure of MPO to alleviate the overfitting problem. |
|
利用自注意力机制优化费米网络的数值研究王佳奇, 高泽峰#, 李永峰,王璐# 天津师范大学学报(自然科学版), 2022 paper / arxiv / 为了探索不使用特定形式的试探态研究多电子系统基态性质的方法,以至多约10个原子的小分子为例,利用神经网络的方法对多电子系统进行求解.此外,利用包含自注意力机制的Transformer结构对费米网络(FermiNet)进行改进, 结果表明:Transformer-FermiNet能够在保证原费米网络结果精度的同时将网络参数的规模缩减为原来的3/4. |
|
2021 |
|
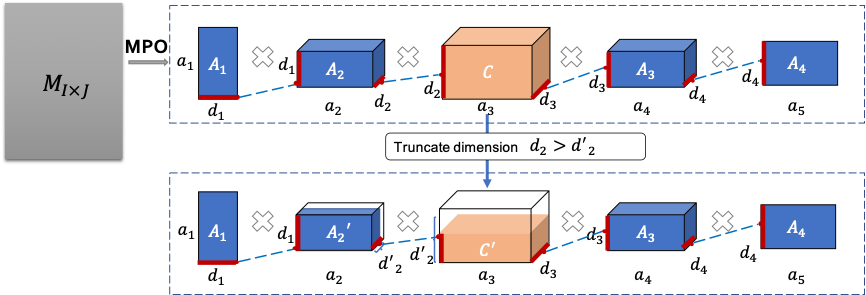
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product OperatorsPeiyu Liu*, Ze-Feng Gao*, Wayne Xin Zhao#, Z.Y. Xie, Zhong-Yi Lu#, Ji-Rong Wen Annual Meeting of the Association for Computational Linguistics (ACL2021), Poster, 2021 paper / arxiv / code / slides / link / This paper presents a novel pre-trained language models (PLM) compression approach based on the matrix product operator (short as MPO) from quantum many-body physics. |
2020 |
|
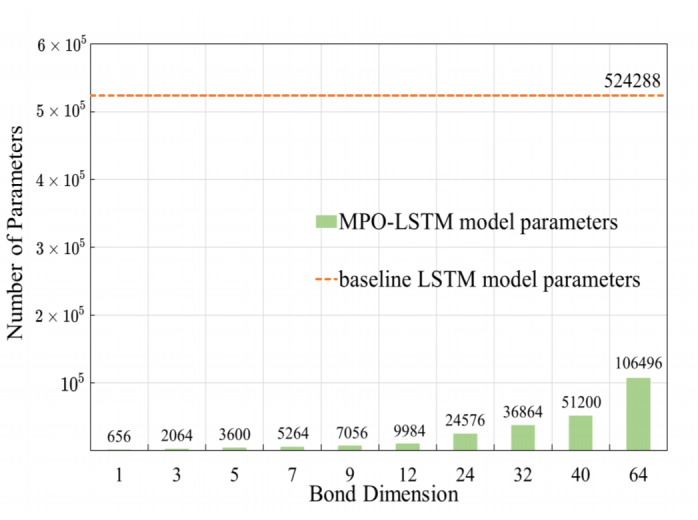
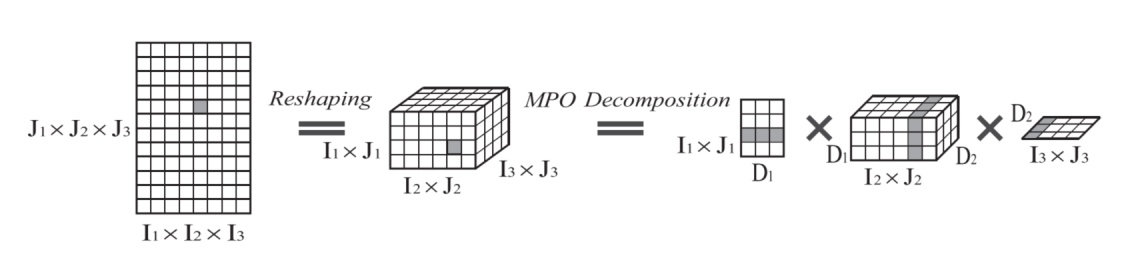
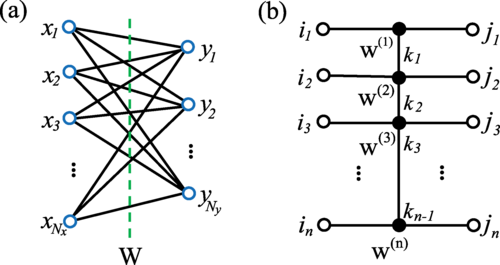
Compressing LSTM Networks by Matrix Product OperatorsZe-Feng Gao*, Xingwei Sun*, Lan Gao, Junfeng Li#, Zhong-Yi Lu# Arxiv, 2020 paper / arxiv / We propose an alternative LSTM model to reduce the number of parameters significantly by representing the weight parameters based on matrix product operators (MPO), which are used to characterize the local correlation in quantum states in physics. |
|
A Model Compression Method With Matrix Product Operators for Speech EnhancementXingwei Sun*, Ze-Feng Gao*, Zhong-Yi Lu#, Junfeng Li#, Yonghong Yan IEEE/ACM Transactions on Audio, Speech, and Language Processing 28, 2837-2847, 2020 paper / arxiv / link / In this paper, we propose a model compression method based on matrix product operators (MPO) to substantially reduce the number of parameters in DNN models for speech enhancement. |
|
Compressing deep neural networks by matrix product operatorsZe-Feng Gao*,Song Cheng*, Rong-Qiang He, Zhi-Yuan Xie#, Hui-Hai Zhao#, Zhong-Yi Lu#, Tao Xiang# Physical Review Research 2 (2), 023300, 2020 paper / arxiv / code / link / In this paper, we show that neural network can be effectively solved by representing linear transformations with matrix product operators (MPOs), which is a tensor network originally proposed in physics to characterize the short-range entanglement in one-dimensional quantum states. |
* Equal contribution # Corresponding author
Professional Services |
Selected Awards and Honors |